We're making slow but sure progress with face recognition...
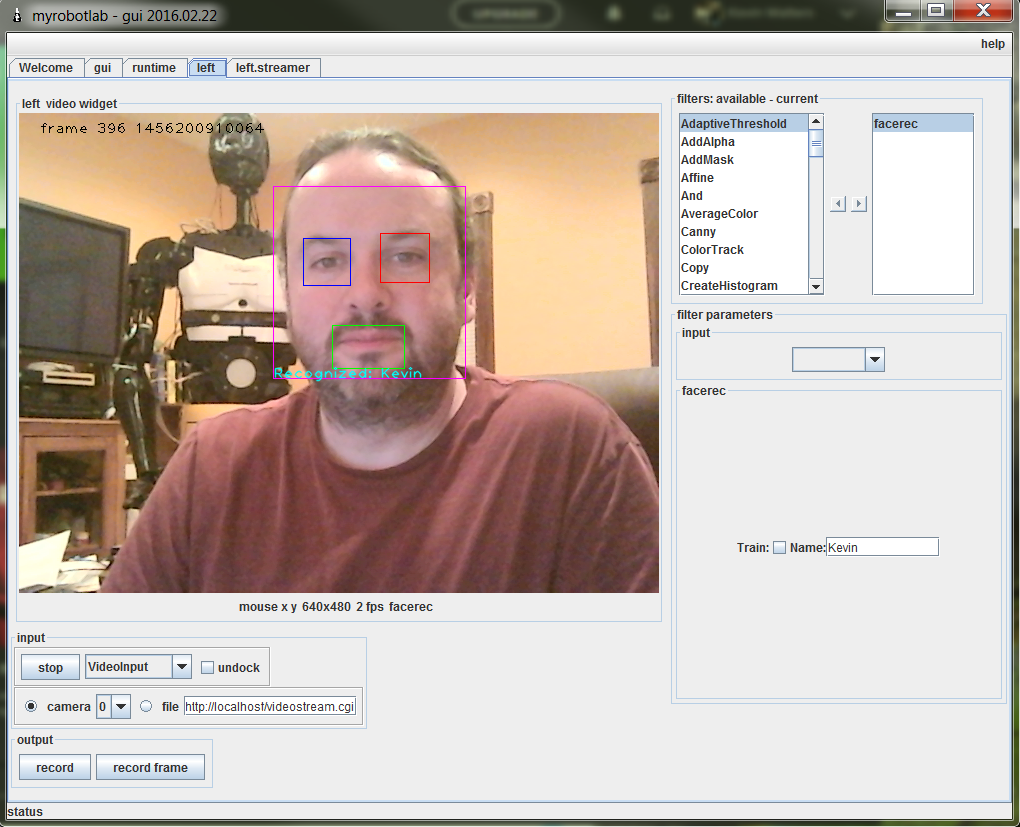
Ok, so thanks to Scruffy-Bob, I've made some progress with facial recognition in MyRobotLab. What we have above is an example of using OpenCV to do face recognition. This uses a FisherFaceRecognizer.
This facial recognition is actually made up of 3 sub classifiers. A CascadeClassifier is used for faces, eyes and mouths detected in this image. Once those have returned their classification, the faces are grouped with the eyes and mouths. The faces that detect 2 eyes, 1 mouth are passed into the classifier to predict who it is.
The classifier returns back a label for the person. The eyes are highlighted in blue and red, the mouth is highlighted in green.
When the "train" button is clicked, the value is the text box is used as a training label. While it's in train mode, if a full face is recognized, that image will be saved off into the training data directory.
Clicking train again will cause the classifier to reload and re-learn from the training image directory.
WOOOHOOO
WOOOHOOO !
_clap_ _clap_ _clap_ _clap_ _clap_ _clap_ _clap_ _clap_
Nice work ! Nice team effort with Scruffy-bob !
Awesome ! You guys Rock ! Excited to peak at it !
Added image masking and retraining mode
I've pushed my first changes to MRL to Git. I guess I'm no longer an MRL virgin. Since I'm new to MRL, Git and Java, I would strongly suggest someone check out my code before committing it to the build.
I've added the face masking functionality I discussed in my other blog:
http://myrobotlab.org/blog/1553
This is completely transparent to the users of the face recognizer, but should significantly improve the recognition performance. It keys off the existance of the filter file, "src/resource/facerec/Filter.png". If you don't want to use the filter, simply remove it from the directory and the recognizer will ignore it.
The second thing I did was change the behavior of the "Train" toggle. If there is no name entered in the box and the Train checkbox is toggled, the face recognizer will simply read (or reread) the existing database of images. This gives you the ability to train the system on the existing faces without learning any new faces.
I'm going to be adding some additional improvements over the next few days. The first thing I'm working on now:
1. Improved sub-feature handling (specifically eyes and mouths). The current recognizer doesn't do a very good job at normalizing pictures if it doesn't have a good handle on where the facial features really are. The current recognizer will sometimes detect eyes and mouths in places where they simply could not be located in normal humans. By improving how this is handled, we should:
A. Get a better training set. Right now, there are lots of images that go into the database that have been wildly distorted. This will significantly reduce the number of inappropriate training images that are stored.
B. Improve speed of recognition. Since we won't be searching the entire face for eyes (which can logically only be in the upper half of the image), the search won't take nearly as long, so overall performance will improve.
There are a couple of other things on my list that I'll attack as I have time. I'll include them here, just so kwatters knows what I hope to tackle next:
1. Normalization of the entire image, not just the face. If there is significant tilt to an image, a normalized image could end up with a lot of blank space along the edges where the face has been shifted. While the face masking should eliminate most of this, it would be better to normalize off the entire image (or a portion larger than just the face area), so when the picture is adjusted, there are no blank areas.
2. Better file handling. I'd like to see the training database broken down by subject (like the OpenCV examples do). This would make it easier to manage all the images without having to wade through (potentially) thousands of images in a single directory. I'm suggesting that the directory structure be:
training/<subject name>/<timestamp>.png
This would guarantee unique names (since using a timestamp should be unique) and it would be easy to see all the names that the system knows just by looking at the training directory. At the same time, I'd like to introduce a limiting mechanism in the training to allow users to limit the number of images saved for each subject. I left the trainer on accidentially while I was looking at something and ended up with 15,000 images. I would also like to make the system capable of handling different resolutions. While I arbitrarily choose 256x256, the system would likely run much, much faster with lower resolution images. It's not an issue on my i7-based laptop, but I suspect the code will eventually have to run on a Raspberry or other lower-powered processor. Having the ability to override the default resolution would be nice.
3. Preprocessing with TanTriggs. This made a significant difference in my original code. Right now, the recognition is fairly dependent on lighting.
4. Standardized prediction results. Your original code actually did a good job at returning a mathematical prediction of whether the image is actually a correct prediction. The current recognizer simply returns the "best guess", which sometimes may not be even close to correct. In other words, if it sees a face now, it will return a name for that face, even if there is no way it could be the correct prediction. Using a standard deviation was a great way to actually do real predictive analysis. My code used a predictive threshold to keep the recognizer from saying it identified something if the percentage was too low. I'm thinking a combination of both my and your original code would be best here.
5. Passing the name to other services. It would be nice to pass the name and potentially the image to another process (so the mouth could articulate who it saw). Since I'm pretty new, I have no idea how hard this would be, but I want the ability to be able to say, "Hello Ron" in my Python program if it sees me. I'm guessing it wouldn't be too difficult since all the other services can pass information back and forth. [I suspect kwatters probably already knows how to do this... hint, hint, hint.]
Best regards,
- scruffy-bob
Progress & feedback
Ahoy Scruffy-Bob! This is pretty awesome , thanks for the feedback and the updates to the Face Recognizer code. You are definitely no longer an MRL virgin :)
There's a lot of stuff here, so I'll just post comments referencing the numbers above. First off it all looks good and I agree with pretty much everything you've said. More details:
pre-1. yes currently. I have the "dePicaso" function that re-arranges some of the eyes/mouth on the face. I suspect we can do much better with that. I put it there really as a place holder, so this is a good area for improvement. Especially because when the face isn't recognized properly, the training images come out mangled.
As for the GUI for it. 1. we generally don't pay much attention to the Swing based gui, and we've been migrating to the WebGui which is based in Angular JS. That being said, the swing gui is very convienent.
I'd recommend adding a JButton to the OpenCVFilterFaceRecognitionGUI to tell the recognizer to "train" off of the test data set. I think this would be easier for people to use , rather than having to know that if you click a checkbox and no name is there, it will train..
If the checkbox is clicked and there's a name. it's in traiing mode. unselecting the checkbox will stop saving images. clicking a "Train" button will reload the images and build the model. What do you think?
Other notes:
1. normalization of the entire image is definitely a good idea, but I think we can address the blank parts of the image due to cropping and rotation by changing the order in which we crop and rotate. I do have some ideas, that if no face is recognized, we could try rotating the original image a few times and try again. I notice that the face detection seems to be very sensitive to rotation.
2. I like the idea of having better organization for the training files. So, yes, I think having a subdirectory for each "subject name" is a good idea. That should also be rather trivial to implement.
3. TanTriggs stuff, I'm sure we can get it ported or find a java implementation. Perhaps there is already something built into OpenCV for lighting normalization. I'd like to learn more about what TanTriggs is doing, but I haven't had the time to dust off the math books.
4. It wasn't obvious to me where the prediction score was that came out of the model. If possible, it'd be nice to know if there was some sort of confidence level, or if we need to roll something ourselves for that. If you find an easy way to get that info from the opencv model, i think it's a great idea.
5. We definitely want the ability to publish things that are found from an OpenCV filter to other services so they can subscribe to that event. This should be pretty straight forward as the MRL framework handles doing the routing of those messages for us. It should be simple enough to define a method called "publishDetectedFace(DetectedFace f)" and when you want to announce to other services that you've detected a valid face you can "invoke("publishedDetectedFace" , f)" .. "invoke" is the magic of the pub/sub framework in MRL. As a comment to this, I'd like to do a review of how other CVFilters are currently setup to recognize and publish data to see if we can come up with a more standardized way of doing it. (we can always refactor and clean up.. for now.. worky is king, as always.)
OpenCV face recognition with MRL- quick question
I can see the rectangles around the eyes or mouth. I selected the FaceRecognition filter and checked Train.
Not sure where the images are getting stored. Any help is greatly appreciated.
Thanks in advance.