
This is often referred to as STT (speech to text) and TTS (text to speech). When I started with computers (eons ago) there were crude text to speech programs. Now with the blooming mobile market the field of study has become extremely active again.
This post is a list of references, and resources for STT and TTS, and some snippets from my own explorations.
For the more enlightening information please read Speech Synthesis and Speech Recognition on Wikipedia.
Speech Synthesis
 I think I first started playing with speech synthesis using MicroSoft's SAPI (Speech API). It had several fun applications, including one nice TTS app in which you could switch voices, control the tempo, speed and volume of the text being processed. It allowed you to copy large blocks of text. Sometimes I would copy something I was interested into it, put on the headphones and do something else while listening to an article (that's pretty nerdy no?). The voice was not "bad", but it was rather mechanical, and after 30 minutes or so became quite grating. I think 10 years ago they were on version 5.1, now there on .. um 5.3 :P
I think I first started playing with speech synthesis using MicroSoft's SAPI (Speech API). It had several fun applications, including one nice TTS app in which you could switch voices, control the tempo, speed and volume of the text being processed. It allowed you to copy large blocks of text. Sometimes I would copy something I was interested into it, put on the headphones and do something else while listening to an article (that's pretty nerdy no?). The voice was not "bad", but it was rather mechanical, and after 30 minutes or so became quite grating. I think 10 years ago they were on version 5.1, now there on .. um 5.3 :P
A good robot would benefit from the ability to understand command spoken to it. So for MRL I started looking around for a TTS engine. My preference was open source, and written in Java. Although the list of TTS functionality continues to grow, I found FreeTTS fit my criteria well. It has a couple voices, one which can only say numerals sound very pleasant. The other which can process any text is still rather "grating"
FreeTTS is a open source speech synthesis engine based on earlier works Festival and Festvox. This is the Wikipedia entry on Festival which includes at the end a nice list of other speech generation applications.
I have been interested in the concept of making not so smart devices much smarter by leveraging the computing power on the web. In one such way I have implemented hacked together one of the methods MRL can do speech generation.
MRL has the capability of generating speech using the FreeTTS package, but as I said I was interested in better quality. At one point I ran across the AT&T Natural Voice Demo site. The voices were really much improved to any previous system I had used. I thought I was try my hand at "cloud computing" and create a Service in MRL which would send text to the AT&T Demo/Service then play it locally. It works rather well. There is a delay in processing the phrase for the first time, but any subsequent times the system reads the sound file locally which is very fast.
Speech Recognition
 Speech recognition is more difficult than speech synthesis. In some ways this is similar to Machine Vision, where useful "meaning" is processed out of a large amount of time critical data. Dragon Naturally Speaking was one of the first programs I heard about which attempted to do this. Unfortunately, I did not have the opportunity to use the software, but have heard good reviews in the past. Microsoft came up with a "speech diction" service. If I remember correctly this was packaged with MS Office, but later they offered it as an add on to the OS. I was not overly impressed with this application, as for practicality, I could not see how anyone could really utilize it. It attempted to be a free word speech recognizer, meaning it "should" have the capability of getting any word which was spoken. Most of the time I attempted to use it (even after training) it produced amusing, but meaningless drivel.
Speech recognition is more difficult than speech synthesis. In some ways this is similar to Machine Vision, where useful "meaning" is processed out of a large amount of time critical data. Dragon Naturally Speaking was one of the first programs I heard about which attempted to do this. Unfortunately, I did not have the opportunity to use the software, but have heard good reviews in the past. Microsoft came up with a "speech diction" service. If I remember correctly this was packaged with MS Office, but later they offered it as an add on to the OS. I was not overly impressed with this application, as for practicality, I could not see how anyone could really utilize it. It attempted to be a free word speech recognizer, meaning it "should" have the capability of getting any word which was spoken. Most of the time I attempted to use it (even after training) it produced amusing, but meaningless drivel.
Sphinx 4
 I decided to incorporate Sphinx 4 into MRL for speech recognition. It was open source, and written in Java, however, there was one caveat. It used the jsapi interface which Sun created, which was/is still not open source, and comes with its own liscense agreement. I have had good luck with it. It has some good documentation and examples. However, it seemed a little "heavy" and overcomplicated. Specifically the configuration seemed delicate and overcomplicated with not enough documentation. But overall when using a "N-word" grammar files it did work.
I decided to incorporate Sphinx 4 into MRL for speech recognition. It was open source, and written in Java, however, there was one caveat. It used the jsapi interface which Sun created, which was/is still not open source, and comes with its own liscense agreement. I have had good luck with it. It has some good documentation and examples. However, it seemed a little "heavy" and overcomplicated. Specifically the configuration seemed delicate and overcomplicated with not enough documentation. But overall when using a "N-word" grammar files it did work.
N-word means you have a recognizer which only recognizes some small set of words. Typically the recognizer does better with smaller sets, and you can build other functionality that relies on these expected few words.
Recently, I was having problems with Sphinx 4 which I think was a contention between FreeTTS code and Sphinx code. I decided to look again out in the intertoobs for a possible better solution.
I believe I found one.
The Google Borg - where all your speech is processed !
I started searching and found that Chrome now has a plugin (apparently since Chrome 11 - where have I been?) which allows speech to text (STT) in form fields. Actually at this point, there are many speech plugins, the one I tried was call "voice search". I installed it and a little microphone appeared next to each input text box. Click the microphone - say something and .. Whoaaa... It's actually pretty good, as in the best I've seen.
Ok, I said to myself. This is worth investigating. Google may have embedded a voice recognizer in chrome... but knowing Google its much more likely that they stream it off somwhere to the Dalles Google Borg to have it processed (remember google maps api?)
To test my theory I started WireShark and took a peek at the network when I was using the new Chrome speech extension.
Chrome uses HTML5 in order to utilize some of the speech capability. I wanted to know what the minimal amount of code would be to get the little microphone. It turns out its very little indead. You just need an HTML page with the following input line.
 |
| Dalles Google Borg |
<input type="text" x-webkit-speech />
You can find an example of this (and other great examples) here - http://slides.html5rocks.com/#speech-input
I made a little html file and added the x-webkit-speech tag and a little microphone appeared. I started WireShark.....
Yep... there it was clear as day.. The sound data was being sent over the wire to a very impressive STT engine !
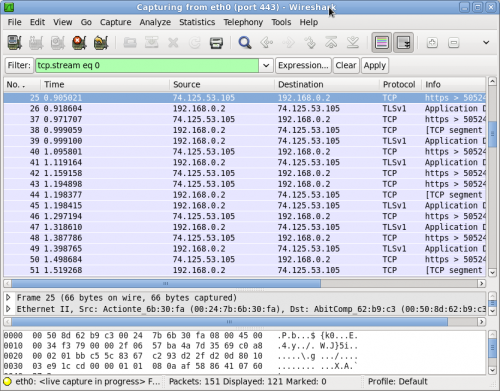
In the past I had used FireFox's add on called HTTP Live Headers - which allow you to see the decrypted traffic going to and from the browser. I did not know of a comparable utility in Chrome, and this HAD to be Chrome since FireFox is not using this speech engine. With a little searching I found Chrome had the ability to report HTTP traffic built in. It also had the same access methods as Firefox where urls are used to get to internal data.
You can try this URL yourself in Chrome and see all the goodies it brings up.
chrome://net-internals/#events
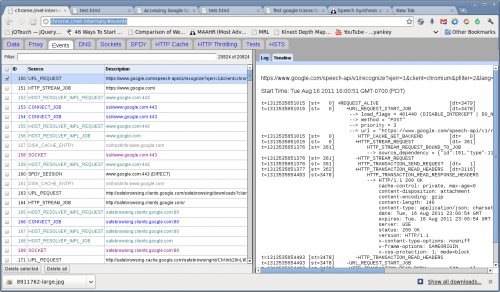
Now I could see some of the details of what was going on. The speech API was doing a post to the following URL
https://www.google.com/speech-api/v1/recognize?xjerr=1&client=chromium&…;
and it sent the sound data as a FLAC attachement.
The return was a GSON - JSON-like object from the server which I imagined contained the textual speech. The next step would have been to try to send a post from Apache HTTPClient or wget or curl to attempt to mimic what the plugin (and Android phones) are doing.
Fortunately, I have learned to search before jumping. I google'd the details of the request -> "speech-api/v1/recognize?xjerr=1&client=chromium"
And BadaBoom ! Someone has been here before !
http://mikepultz.com/2011/03/accessing-google-speech-api-chrome-11/
Hello Mike Pultz ! Arrived there 5 months earlier ! And it appears someone has already someone has written a Processing plugin.
Now to put it in MRL !
2011.08.18
I have put it into a pre-alpha MRL - It works but there are some details which need to be addressed.
- Regrettfully, non of Sun's JVMs implement a fuction which allows examining the sound level of the microphone - In order to process speech, one is interested in the "speech" part, and this is determined or triggered by the sound level of the microphone.
- Threading & Timings - The Google service is amazing as it will recogize "ANY" word will impressive accuracy - The only drawback relative to Sphinx is the time it takes.. Some of the time could be optimized on MRL's side
Future
Soon I will be preparing a test to do visual recognition and learning with feedback and guidance with voice.
References
- AT&T online speech demo - http://www2.research.att.com/~ttsweb/tts/demo.php
- Festival FestVox TTS - http://festvox.org/festival/
- FreeTTS - a Java TTS engine - http://freetts.sourceforge.net/docs/index.php
- Sphinx 4 STT Java engine - http://cmusphinx.sourceforge.net/sphinx4/
- Nice list of Linux STT engines and applications - http://en.wikipedia.org/wiki/Speech_recognition_in_Linux
- Mike Pultz excellent article on his own Google STT discoveries http://mikepultz.com/2011/03/accessing-google-speech-api-chrome-11/
- Processing plugin http://stt.getflourish.com
- List of STT and TTS engines http://linux-sound.org/speech.html
- Voce a combination Sphinx 4 FreeTTS library - http://voce.sourceforge.net/