An interesting link - http://en.wikipedia.org/wiki/Content-based_image_retrieval (CIBR)
Update 2013.03.31
.png){kind=link}
.png)
Although not very visually exciting, I've made progress. In the above picture the Tracking is looking for foreground objects, but will save background objects off to Cortex. The part that has been updated is Cortex now can pull off one of the saved background images and run through further processing simultaneously. So although I was stationary enough to become "background" and was hidden from tracking, the Cortex still found my face. At this point the Cortex should tell tracking were to set 2 LK points to track (corner of eyes are usually good). Additionally it will take snapshots of the bounding box area to save as templates for template matches. This should help in Face Identification in addtion to Face Detection.
If you look at the Big Picture Link you can see some of the structure of the implemented memory. Part of memory is building up context. When a face is found it will be sent to the /processed/faces node - You can see 2 background image nodes - copies of these nodes have been processed and put under faces - since faces were found in them. You can also see a bazillion /unprocessed/foreground objects - heh, that's something I have to fix. Each Image node is currently has a timestamp name, but it can also be indexed under location. This will be important when the concept of "last known location" on a pan tilt kit is wanted. "Known" versus "Unknown" seems to be very basic branch of context.
Update 2013.03.28
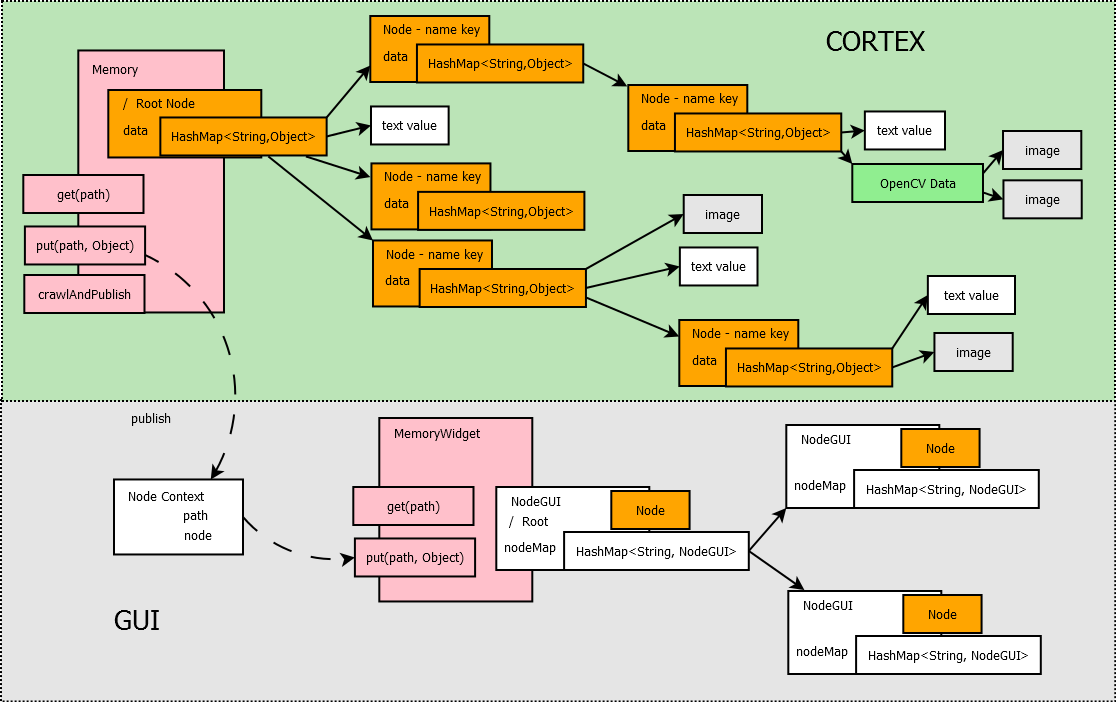
The data structures for the memory and the display of memory are now pretty solid. It's a Radix Tree structure implemented with a String keys and Object values. This means, it is very quick to lookup a node, and the node can contain any type of data. Additionally, I made the interface accept a simple XPath notation.
So any node in memory can be described and retrieved through a path starting with
/ <- root
/object/known/ball <- example
This seems to be an effiecient was of storing and structuring memory. It's quick and hierarchical. It's also general enough to store any type of information, and can grow in breadth and width. Now it's time to start filling it ;)
Update 2013.03.19
.png)
Here memory is being pushed into the tree - and the "cortex output video widget" is now showing the "original" input of the background memory node. Currently, data from the cortex is just being blasted to the video widget, and its not "controlled" by the user selecting on the desired node. I have to change this next.
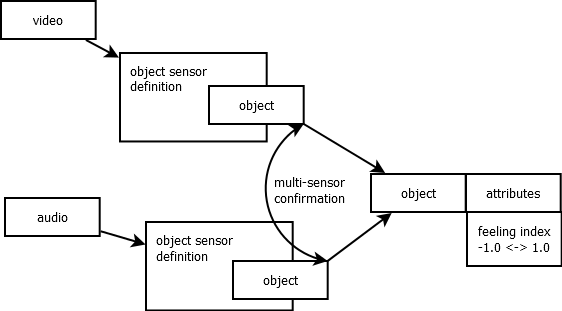
This is an object defintion diagram, after listening to the very beginning of RadioLab's "Solid as a Rock" program. It describe a psychological condition where different input stimuli (here as object sensor definitions) disagree with one another. The patient then might see there mother and "believe" that she was an imposter.
.png)
Yesterdays tree view was "theoretical" - this morning I've connected the actual memory maintained by the Cortex to this display... It's a bit "rough" obviously, but it dynamically updates the display - as memory grows you can see it build the tree. Next, I'll need to work on displaying "special" image data. What should happen is you could open the MEMORY_OPENCV_DATA - and display the images saved from processing. For each memory node there is a considerable amount of textual data. Cix had a good idea of displaying this in tabular form. It would clean up the tree alot. So you could highlight a "background" Node and the display on the right would change to a list of textual - name=value pairs. Once the display is semi-satisfactory I can start working on the Cortex "Background Processing & Key Extraction". Displays certainly take a lot of effort - but its critical to be able to visualize this information, its heirarchy, and how its stored...
-
display special types like OpenCV data - test cyclical references
- create tabular view
- put in awt thread safe updates
- events from tree figured out
- modes of auto-update all versus update only user explored nodes
Update 2013.03.18
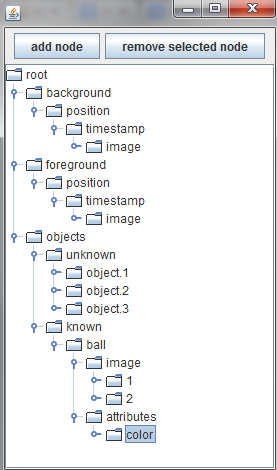
I've been working on the "Display Memory" part of the Cortex. Its important to be able to easily see what is going on with the Cortex's memory. The memory of the Cortex can be large and complex. It will have contexts, relations, attributes, and many different types of info. Some information will be textual, and some image information. In order to navigate through this complicated structure I chose a tree representation.
It hopefully will show parts growing depending on information flowing in through the video feeds. Additionally, I thought I could allow the interface to accept modifications from the user too (the gui currently allows this). Then even if it correctly recognized a "ball" you could easily modify it to a different word "globe" perhaps, or add more attributes. Should be fun ;)
Holy Cobwebs ! The Cortex service has grown - at least the planning of it has grown. It's still a mess of a map, but I think its closer.... Big Link
.png){kind=link}
![]()
Some recent discoveries :
- Figured out how the Tracking should start up - initializing the sub systems then put itself into an idle state - which it will immediately start learning the background etc...
- Cortex & Tracking services will be able to attach to one another
- Tracking service is the "Eye" - or top two boxes in the diagram
- Cortext service is the bottom 4
- Image data is continually being sent into the Tracking Service - but it only sends "key" images to Cortex
- Cortex is hungerly devouring and processing any image data it can get from Tracking
- The Tracking Service is no a critical part of this system - I keep waffling back and forth - put everything together? Or break it out into different services :P
- OpenTLD (aka Predator) seemed like a great algorithm - I have not looked at it much beyond watching the video and discovering that the TLD = Tracking, Learning & Detection.
- The TLD is missing an "I'' for Identification - key info can be added, stored and search. This helps establish the all important "context". For example, you don't go looking for full sized cars in a toybox, although "toy" cars would be apropos. Also if you don't know something is what do you do ? That's right, search google. Why wouldn't a robot do the same thing? More relationships can be constructed that leads to a rich internal representation of the robots surroundings.
- Mapping is extremely important for robots, expecially mobile ones. I think this is an important part of the visual cortex, and we go about our daily activities with this part of our brain constantly working. It has to happen so much and so often we are mostly never conscious of it. RadioLab had a program which went through the process of what humans do when they spatially navigate. I'll try to incorporate some of the strategies presented there.
- More re-design - Tracking Service is alive again :P and it does the "Motion Detection" & "Tracking" of the diagram.
The Grover's Nose Problem ...
I cut this snippet out of the shoutbox - because its an intersting problems and repeated challenge of making computers pick the "right" answer not the technically correct one...
|
GroG: it seems like its actually fudging it a bit ... I mean techincally your hand and grovers nose are correct answers .. they just aren't the "desired" answers
|
|
bstott: Ok, going to link to learn.
|
|
GroG: so that's what I mean by "stable"
|
|
GroG: yet all came into view during the "test"
|
|
GroG: or GROVERS NOSE !
|
|
GroG: no one yelled out ... YOUR HAND !
|
|
GroG: I mean grover passed this test right ?
|
|
GroG: you'll see a simple test which I would like the computer to pass
|
|
GroG:
I gave nomasfilms this example - so if you watch this video - http://www.youtube.com/watch?v=FClGhto1vIg |
|
GroG: well, I'm starting off with baby steps .. and I think I wanted stuff "stable"
|
|
bstott: stable- filter. OK, does that mean the video feed is stable but, not necessarily the environment?
|
|
GroG: Stable (as far as I know) - is stabilization of a filter on a live video feed.. once that happens - the data from it can be processed in the background on a different thread at "fast speed"
|
More helpful chatting with bstott - snipping it out to save it...
|
GroG: it's the back end (brain) which figures out what it is and whether its important to spend more time on
|
|
GroG: it made some sense to me, because your eyes are always looking for "new" stuff or motion - but they don't necessarily "figure" out what they are looking at
|
|
GroG: munching and crunching - until it gets its next image from the eye part (top blue & green squares)
|
|
GroG: trying to pull key information out of the images
|
|
GroG: and the brain munches on it with all kinds of algorithms (that's the orange blocks)
|
|
GroG: but at some key point - it throws data to the back end (brain)
|
|
GroG: needs to be lively and responsive..
|
|
GroG: its also controlling the tracking servos
|
|
GroG: so if you look at the top half of the diagram - its doing "quick" stuff - looking at each frame of the video
|
|
GroG: Ya right .. ok |
Visual learning at its best.
Visual learning at its best. I know nothing of FSMs, but I can understand your wonderful diagram. Now, lets say you wanted a robot following this FSM to look for and track a certain object it has already "learned". Where in the diagram would this command enter the matrix? Let's say it has learned "tennis Ball" or in your case "Beer", and there was one in view. Would the object be need to be separate from the background, or would it then be possible to introduce the robot into a completely new environment and still have it locate the object?
Context
What is shown at the top of the diagram, is a way to distinguish "old" background from "new" foreground, and a systematic way of processing the data so it will be available later. It turns out seperating old from new or foreground from background is a fairly robust way to segment an object for learning. We need a way to say "This is a ball" and isolate the ball (or whatever the target is) from the rest of the image.
Once learned a template can be used to match in a completely new environment. "Template" matching is not the most robust method of matching learned objects in a new scene. It's quite "brittle". But, there are many other strategies . My idea is that a myriad of other algorithms can extract key information from the image - even if its not being actively view anymore. This is the "extract key algorithm & list of algorithms" in the diagram. These will extract "keys" parts which will augment the robustness of matching objects in new environments.
To answer your question, what you describe is the diagram with the blue Motion Detection block removed. The video feed would go directly into Background Processing and Key Extraction without the benefit of foreground/background seperation. If it was previously learned, then there would be a high likelihood it would be matched, possibly with template information saved from a previous session.
There is also the possiblity you would create a search target, and the system would use this in an attempt to find the object in previously processed data.
A great example would be if you could ask your robot if it has seen your keys, and the robot replied - "They were on your dresser, but they are not there anymore"... ;)
Simply put, the concept I have is about building and refining a large amount of data with many different algorithms. Not just raw image data or templates, but also average color, image info without shadows or highlights, edges, textures, size, position, time, range, and key words all are attributes and relations which can aid in searching successfully... and after all we want to find our keys !
Architecture
Hi GroG,
which architecture will be adopted ? the Tracking-FSM service will be always connected to the cloud (to share the informations collected), or it could run stand-alone (I mean without internet connection, because I'm assuming the cloud is on the net) ?
I'm thinking at domotics: many IP cam (or cam security system) could be connected to MRL so, we could talk with the our house (for example personalized welcome message, a search target and so on...). In this scenario, I am a bit concerned about the privacy... I shouldn't like kwnow that my habits are shared over the net !!
Default Secure
The design shall work completely locally by default. It will take additionall effort to get data from the web/cloud and more effort to publish.