
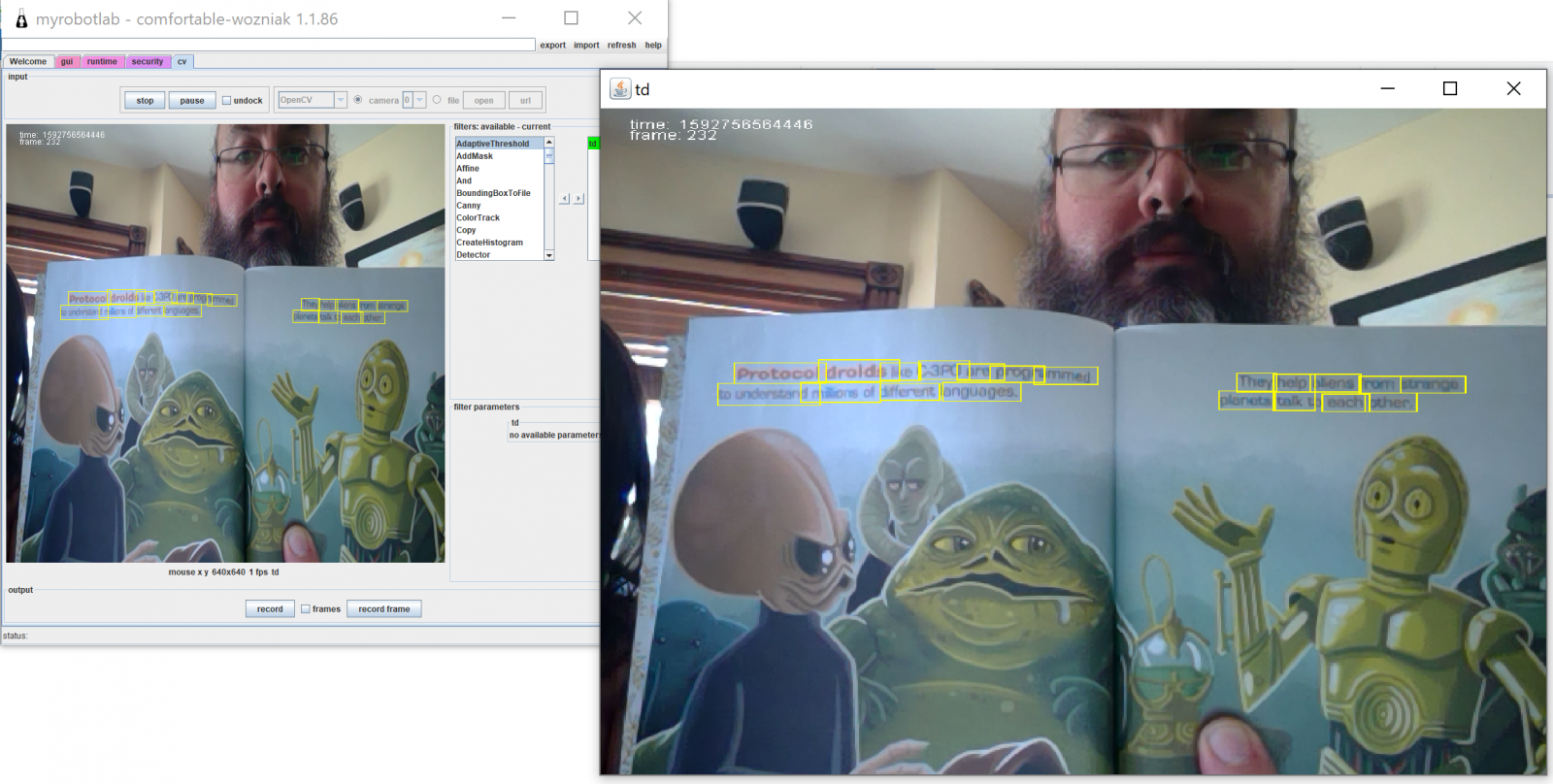
Update: So, now I have the east text detector integrated into the "text detection" opencv filter ( PR pending). It finds regions of text in an image or video feed. It cuts, crops and rotates the detected regions of the image. The cropped image thenis sent through the tesseract service to perform OCR. Tesseract returns the text for each cropped image. It's starting to really come together. one fish.. fwo fish... red fish... blue fish.
I've been working on porting over the text detection opencv example to MRL.. This is a preview of the work in progress.
Way to go Kwatters!
It was a challenge when I made Junior read a Christmas story a couple years ago.,.. Hopefully it is becoming easier!
May have to get Junior on a summer reading program...
Kyle
Ahaha :) Awesome ! I like
Ahaha :)
Awesome !
I like your book selection.
I was looking at your pr, and this is a filter that isolates words? Is the DNN built trained on recognizing characters? Or is it trained on 'text' without an understanding of characters ? Then the next pass is Tesseract ?
Very cool !
text detection and recognition
currently that code is a bit of a mess as i'm just seeing how to wire it all together. First step is to get the east text detector.. run that on the image.. that produces a whole lot of overlapping recommendations..
next put a threshold on it to filter out the low quality stuff, and pass the remaining items through an algorithm called "non maximum supporession" to remove the overlapping / near duplicated detected regions..
that algorithm produces "RotatedRect"s that contain the four points of the corners and the angle that the text is rotated at.. then we can cut & crop.. & rotate the images (using a "fourPointTransform") .. to get just the text region...
at this point, we could apply a little more contract adjustment if we want. or we can stick the data into tesseract to get the text out of it. there was another DNN that does the text recognition also.. I haven't wire that in yet. It'll be interesting to see which one does better.
I guess lastly, would be to assemble and order all of the word fragments into the text detected on the page and cause that to publish the text found in the image.
The final demonstration would be to say "read it" to the robot.. and have it read what it sees...
this is still very much a work in progress, but i've been steadily chipping away at it.. ultimately, it'll need to be refactored to create a DetectedText object that can be added to the OpenCVData....
Awesome ! I guess lastly,
Awesome !
I guess lastly, would be to assemble and order all of the word fragments into the text detected on the page and cause that to publish the text found in the image.
Ya, I was scanning for a publishText ;)
You have it as a pr - It's nice to look at before finished ...
I often prefer paintings like this ... For me, works in process are usually more interesting than the finished pieces.
Do you need it merged ?
"2 weeks" ...
yeah.. so it's definitely work in progress. basic plumbing is in place, once i have the ocr part dialed in with the ordering and invoking the publishText, then we can do a PR... I'm happy you've got eyes on it. I'm feeling like we have a shot at making this work...
I would lreally like to see this implemented...
Wohooo ... I would really like to see this implemented Sir.k
The person I made the single handed PS4 controller a while back would benefit from this, he has been pointed in this direction...