This is a basic demonstration of software which I have written which does a form of machine vision for object detection and ranging. I will continue to develop it for use with loki advanced robotic platform and other robots. The software is written in java and is theoretically capable of running on any platform capable of supporting the java virtual machine. Unfortunately my software will not run on microcontrollers (yet) :D
Setup
This particular setup consists of 2 X 3Com Homeconnect Webcams I bought off of Ebay about 4 years ago. They are fairly good cameras for the price ($12 to $15) and more importantly they have Linux drivers readily available. The computer is a donated Intel Celeron with a 2.60GHz CPU. The OS is Fedora Core 8 with a variety of other fun free software packages. Everything is shifted red in the images because I had to remove an internal cloudy blue filter from inside the cameras. Previously the cameras were extremely blurry. The software should be able to handle any webcam as long as it has a Linux driver. I have not written a Window$ interface (yet). In fact by today's standards my cameras would be rated as very poor quality. They have a fairly slow frame rate, sometimes as low as 3 fps. They have a maximum color resolution of 320 X 240 pixels. I continue to use these cameras for 2 reasons. 1. They are cheap. 2. I believe that as I develop the software for the worse possible sensor - it will work much better for better cameras. I have done some obstacle avoidance tests and routines before, but for this test I will only be exercising object detection and the beginnings of some simple ranging.

2 webcams on motorized mount
Computer: Intel Celeron with a 2.60GHz CPU
Cameras: 2 X 3Com Homeconnect Webcam for $15
Software: A Java program I wrote which uses some Java Advanced Imaging
Operating System: Fedora Core 8
Target: Duplo blocks and a variety of other objects
Background: small light beige fabric on the floor, my wife let me borrow it because she watched part of STeven's video and said to me, "Geeze, that is clean, you better not put our basement carpet online!"
Definitions and Descriptions
Here is a list of definitions and descriptions relating to the video in the 4 applets displays. Although, a web page and an applet is being utilized for the display, any application which can show a series of jpeg images could be connect to the robot. I am using GWT for a control panel of loki, so an applet display seemed to be a logical choice. I can view and control from anywhere on the internet (Bwah Ha Ha).
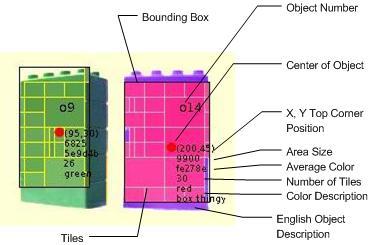
Bounding Box: a rectangle drawn around all the tiles of an object
Object Number: an arbitrary number assigned to a object
Center of Object: center of object derived by the bounding box width and height divided by 2
X, Y Top Corner Position: top corner pixel location of the bounding box. The X (horizontal component) will become important inStereo Vision when determining Horizontal Disparity. This will help in ranging the distance of objects.
Area Size: total size of tiled area in pixels
Average Color: average color of all tiles grouped with this object
Number of Tiles: number of tiles grouped with this object
Color Description: at the moment it can only handle red green or blue and this is done finding which value of the average color is the highest, I might add "martha stewart's winter wire color" as another option as soon as I figure out what RGB value that is.
English Object Description:this is derived by a threshold of how many tiles fill the bounding box. If it is enough then it will consider it a "box thingy". The bounding box could be changed into other templates. For example, "triangle thingy" or "circle thingy". With range added, dimensions can also be calculated. With that comes a higher order of conceptualization of "box thingy". It could be a "12 inch X 18 inch black box thingy 4 feet away". This could match with "Computer Screen" or some other appropriate data item. As you can see, this can be in Danish or English.
Overview of Algorithm
I did some previous experiments with a Sobel and Canny operators but my implementation seems to have brought out a significant amount of noise. I would like to revisit these algorithms at a later time.
What I am currently doing, I think, is some form of sparse color blob detection?
Here are the individual parts:
- recursively split based on a max color deviation from a sparse sample
- begin grouping on a tile-size threshold
- recursively group adjacent tiles based on a color threshold
- match objects based on size color and other variables
- range object in a 2 camera system with horizontal disparity of matched objects
Splitting
I have done tried some experimentation with edge detectors. It was seemed rather noisey for measurements and appeared to increase the correspondence problem. After thinking about it, if my objective was to match objects in two extremely divergent quality cameras, I would try to match the "largest colored area" first. I believe this might be referred to as Blob Detection. I also figured that trying to determine the as many characteristics of an object possible, in one camera, would help me find the corresponding object in the other camera. I mean, if you know its a "Shoe" in one camera picture, you can find the "Shoe" in the other camera without much difficulty. So, the more data I processed and refined the object in one camera, the higher the possibility of matching it correctly in the second camera. So the first part of this algorithm was to split the screen up into tiles of color.

If a color difference threshold is met the tile is divided into 4 quadrants tiles, the 4 tiles are recursively split or ignored depending on this threshold. I created indexes for the tiles' corners. This was an optimization to search adjacent rectangles. In order to support this, the splitting need to be divided equally divided into 4 parts.
This means the 320 X 240 image can be divided 4 recursive times. The width can be divided a couple more times equally – that is why the smallest tiles are rectangular rather than square.
Grouping
After splitting the second algorithm would group selected tiles together.

The particular algorithm I used will not begin to group anything below a certain size-threshold, which I think is one of the biggest short comings at the moment. I will probably change this in the near future. Once a tile has been identified as being "big enough" adjacent tiles are searched and if the color difference is within a certain amount, the adjacent tiles are joined to the object. This is done recursively until all the corners of the grouped tiles have been checked.
Filtering
There is not much filtering going on in this experiment. I filtered the background object out, because it would put a red dot in the center of the screen with a bunch of statistics, and I did not want that displayed at the same time other objects in the view were being processed. It's a very lame filter, I just grab any object above a certain brightness, since in this scenario the background was bright. And as you might have noticed, that is why certain other object were also filtered out. The white cat hair would be an example, also part of my hand was filtered out because of this silly background filter.
Ranging

I have not finished this ranging section, because I keep finding things which might aid in reducing the correspondence problem in single camera mode. But I did put a few indicators in so I could begin some calculations. The points on any corner of the bounding box could be used to derive range information. The X position is used to find the horizontal disparity and using trig or a simple look-up table, the range can be calculated. In this particular instance the distance to the Red bricks is 38.1 cm (15") and the distance to the Green bricks is 25.4 cm (10").
To Do
Optimizations - there are many serious optimizations that could be done, but at the moment on limited time and having too much fun being the mad scientist I am saving that for later.
Other Algorithms - The data coming from a video camera is huge. On my crud cameras there is 320 X 240 X 3 X 3 bits flowing per second. There is a vast amount of interpreting which could be done. So many algorithms, so little time. Humans, after 6 billion years of evolutions seem to have perfected it on many different levels. For example, human's multi-dimensional understanding of objects and our understanding of perspective will allow us to easily range, navigate, and identify aspects of the environment around us even with an eye missing! If I only had 6 billion years. Here is a list of some other algorithms I am interested in.
- Determining location and direction of light source
- Handling reflections and shadows better
- Revisit Sobel and Canny operators as another processing unit
- Template / neural network identification (see below)
- Determining distance through Jittering (moving the camera back and forth on a horizontal plane to generate a 3D map)
- Make a little motor which can move the cameras further apart or closer together, the further apart they are the better at ranging long distances
Identification - I am interested in being able to identify objects. I was thinking of using templates stored in a database. I intend to hook up a neural network to resolve the statistical complexity when the robot finds something in the environment and tries to match the appropriate template. An interface where the robot drives around and locates an object in its environment. It will process against the neural network and come up with a guess. At this point I will be able to sadistically train it :D. It will drive around and pick up a sock on the floor and ask "Towel?". I then will punish... I mean train by saying "No" .. Then it will make another template to be stored in the database... And hopefully I won't find it wiping down the table with my socks.
Console to manage Inputs and Outputs - The software currently can manage inputs and outputs of video data streams. In this experiment the video stream was put in 4 queues. Two of the video queues were left undisturbed while the other two were fed through the splitter, the grouping, and the filter before being converted into jpegs and sent to the applets. The streams can be forked apart or joined back together. At the moment there is no console to construct or tweak parameters of the algorithms. So that is on my todo list too..
3D & 2D mapping - creating, storing, recalling, and comparing maps in a database or internet (google maps, IFRIT, etc)
Context creation - the idea that every single frame does not need to be processed and thrown away. But to store the useful results of processing in a database to be referred to later.
Trac Project and SVN repository - create an open source project so anyone who wants to try it or improve it can...
Splitting and Grouping Processor seperated - at the moment they are in the same processor, but they should be seperated since it may be desirable to split and send to a different processor ie. Canny Sobel or something else.