The i01.ear works is recognizing special characters great, but in log i get this:
[New I/O worker #3] [INFO] Recognized : >Zamknij dłoń<
[New I/O worker #3] [INFO] Publish Text : Zamknij dłoń
[python.input] [ERROR] ------
Traceback (most recent call last):
File "<script>", line 1, in <module>
File "<string>", line 1758, in heard
UnicodeEncodeError: 'ascii' codec can't encode character u'\u0142' in position 9: ordinal not in range(128)
at org.python.core.codecs.strict_errors(codecs.java:208)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at java.lang.reflect.Method.invoke(Unknown Source)
at org.python.core.JavaFunc.__call__(Py.java:2426)
at org.python.core.PyObject.__call__(PyObject.java:431)
at org.python.core.codecs.encoding_error(codecs.java:1538)
at org.python.core.codecs.PyUnicode_EncodeIntLimited(codecs.java:1211)
at org.python.core.codecs.PyUnicode_EncodeASCII(codecs.java:1170)
at org.python.core.codecs.encode(codecs.java:165)
at org.python.core.PyString.encode(PyString.java:3896)
at org.python.core.PyString.encode(PyString.java:3888)
at org.python.core.PyUnicode.unicode___str__(PyUnicode.java:667)
at org.python.core.PyUnicode.__str__(PyUnicode.java:662)
at org.python.core.PyString.str_new(PyString.java:164)
at org.python.core.PyString$exposed___new__.new_impl(Unknown Source)
at org.python.core.PyType.invokeNew(PyType.java:494)
at org.python.core.PyType.type___call__(PyType.java:1706)
at org.python.core.PyType.__call__(PyType.java:1696)
at org.python.core.PyObject.__call__(PyObject.java:461)
at org.python.core.PyObject.__call__(PyObject.java:465)
at org.python.pycode._pyx3.heard$30(<string>:2353)
at org.python.pycode._pyx3.call_function(<string>)
at org.python.core.PyTableCode.call(PyTableCode.java:167)
at org.python.core.PyBaseCode.call(PyBaseCode.java:138)
at org.python.core.PyFunction.__call__(PyFunction.java:413)
at org.python.pycode._pyx58.f$0(<script>:1)
at org.python.pycode._pyx58.call_function(<script>)
at org.python.core.PyTableCode.call(PyTableCode.java:167)
at org.python.core.PyCode.call(PyCode.java:18)
at org.python.core.Py.runCode(Py.java:1386)
at org.python.core.Py.exec(Py.java:1430)
at org.python.util.PythonInterpreter.exec(PythonInterpreter.java:276)
at org.myrobotlab.service.Python$InputQueueThread.run(Python.java:137)
------
[python.input] [ERROR] python error PyException null
Here is the screen shot from the i01.ear service:
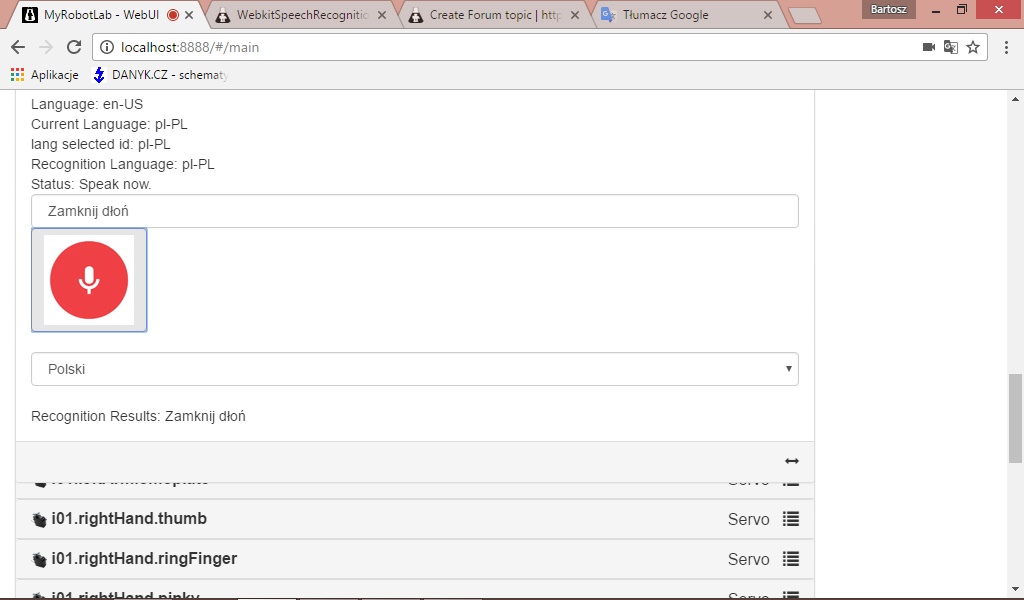
caracter encoding can be a
caracter encoding can be a pain to use
There is several character encoder/decoder that can be use so every character can be recognized
what happen in your case is that the 'ear' encore the answer in a format (probably UTF8) that is not recognized by MRL. You need to tell the program which decoder to use so it can read the string.
Without knowing more about what you are doing, it's hard to guide you how to fix the problem
for my German umlaute I use
for my German umlaute I use this function in the python script:
Eureka here is the sample
Eureka here is the sample without any replace in pyton.
I think that works in other languages but need to search for UTF coding.
the simplest way