Connector and Document Processing Pipeline Framework
So, my work work is really around building custom search engines. I am constantly re-inventing the wheel of creating a framework that can crawl a data source (such as a website , rss feed, file system, database.. etc)
Components
- Document - The basic item that is being crawled. This could be a file on disk with it's metadata, it could be a url and the associated html from the web page. At it's nature, a document is a globally unique identifier with a map of field name to list of values.
- Connector - a service that can scan to create new documents. Connectors can crawl data. This could be something that scans a file system, crawls web pages, or run a select statement against a database.
- Stage - This is the building block for all transformations that occur on a document in its lifecycle. These stages could do something simple like put the current timestamp on a field called "date" on the document, or more complicated things like extract the text from a pdf file and set it on the "text" field of the document.
- Pipeline - This is a sequence of stages that a document will pass through.
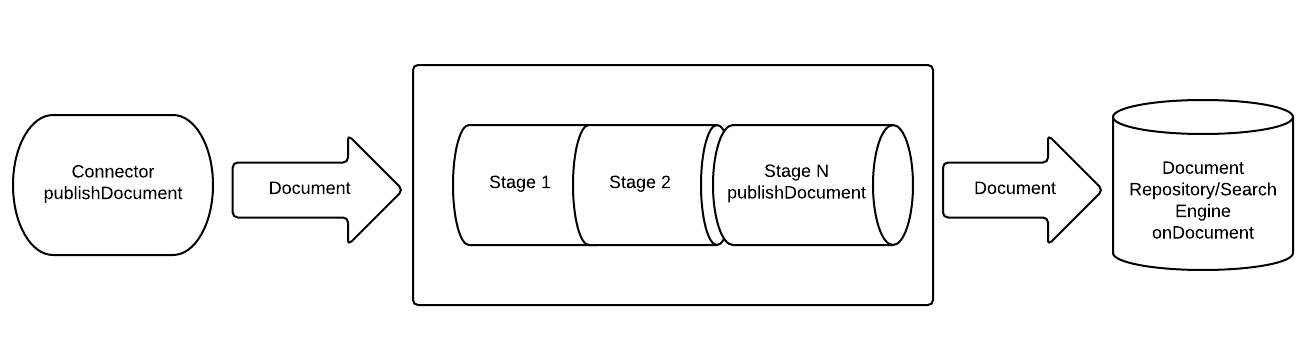
The basic flow / model is something like the following:
1. AbstractConnector service in MyRobotLab will crawl for documents. The document will be published. This service implements DocumentPublisher
2. The DocumentPipeline service is started that holds a workflow and a set of stages for that workflow. This service implements DocumentListener (and DocumentPublisher, to some extent.)
3. The document pipeline service listens for documents published by the connector. When a document arrives, it's passed sequentially down the set of stages.
4. Each stage provides a method called processDocument. The processDocument ususally manipulates the metadata on the document as it goes. These changes are set back on the document before it passes to the next stage.
5. TODO: When the document exists the last stage of the pipeline it will pubish the docment to a service that is listening on it.
6. The Solr service in myrobotlab will relay documents to a Solr instance running somewhere for indexing. This service implements DocumentListener
This is really just the start of a much larger scope of functionality that I'll be working on that will allow MRL to interact with news feeds, document repositories, databases, file systems, etc...
Welcome to big data, text analytics and search for MyRobotLab!